http://www.matrix67.com/blog/archives/5100

 2012-12-15 13:46|
2012-12-15 13:46|  47 Comments | 本文內容遵從
47 Comments | 本文內容遵從
數論,數學中的皇冠,最純粹的數學。早在古希臘時代,人們就開始痴迷地研究數字,沉浸於這個幾乎沒有任何實用價值的思維遊戲中。直到計算機誕生之後,幾千年來的數論研究成果突然有了實際的應用,這個過程可以說是最為激動人心的數學話題之一。最近我在《程序員》雜誌上連載了《跨越千年的 RSA 算法》,但受篇幅限制,只有一萬字左右的內容。其實,從數論到 RSA 算法,裡面的數學之美哪裡是一萬字能扯完的?在寫作的過程中,我查了很多資料,找到了很多漂亮的例子,也積累了很多個人的思考,但最終都因為篇幅原因沒有加進《程序員》的文章中。今天,我想重新梳理一下線索,把所有值得分享的內容一次性地呈現在這篇長文中,希望大家會有所收穫。需要注意的是,本文有意為了照顧可讀性而犧牲了嚴謹性。很多具體內容都僅作了直觀解釋,一些「顯然如此」的細節實際上是需要證明的。如果你希望看到有關定理及其證明的嚴格表述,可以參見任意一本初等數論的書。把本文作為初等數論的學習讀物是非常危險的。最後,希望大家能夠積極指出文章中的缺陷,我會不斷地做出修改。
======= 更新記錄 =======
2012 年 12 月 15 日:發佈全文。
2012 年 12 月 18 日:修改了幾處表達。
2012 年 12 月 18 日:修改了幾處表達。
======== 目錄 ========
(一)可公度線段
(二)中國剩餘定理
(三)擴展的輾轉相除
(四)Fermat 小定理
(五)公鑰加密的可能性
(六)RSA 算法
(二)中國剩餘定理
(三)擴展的輾轉相除
(四)Fermat 小定理
(五)公鑰加密的可能性
(六)RSA 算法
(一)可公度線段
Euclid ,中文譯作「歐幾里得」,古希臘數學家。他用公理化系統的方法歸納整理了當時的幾何理論,並寫成了偉大的數學著作《幾何原本》,因而被後人稱作「幾何學之父」。有趣的是,《幾何原本》一書裡並不全講的幾何。全書共有十三卷,第七捲到第十捲所討論的實際上是數論問題——只不過是以幾何的方式來描述的。在《幾何原本》中,數的大小用線段的長度來表示,越長的線段就表示越大的數。很多數字與數字之間的簡單關係,在《幾何原本》中都有對應的幾何語言。例如,若數字 a 是數字 b 的整倍數,在《幾何原本》中就表達為,長度為 a 的線段可以用長度為 b 的線段來度量。比方說,黑板的長度是 2.7 米,一支鉛筆的長度是 18 釐米,你會發現黑板的長度正好等於 15 個鉛筆的長度。我們就說,鉛筆的長度可以用來度量黑板的長度。如果一張課桌的長度是 117 釐米,那麼 6 個鉛筆的長度不夠課桌長, 7 個鉛筆的長度又超過了課桌長,因而我們就無法用鉛筆來度量課桌的長度了。哦,當然,實際上課桌長相當於 6.5 個鉛筆長,但是鉛筆上又沒有刻度,我們用鉛筆來度量課桌時,怎麼知道最終結果是 6.5 個鉛筆長呢?因而,只有 a 恰好是 b 的整數倍時,我們才說 b 可以度量 a 。
給定兩條長度不同的線段 a 和 b ,如果能夠找到第三條線段 c ,它既可以度量 a ,又可以度量 b ,我們就說 a 和 b 是可公度的( commensurable ,也叫做可通約的), c 就是 a 和 b 的一個公度單位。舉個例子: 1 英吋和 1 釐米是可公度的嗎?歷史上,英吋和釐米的換算關係不斷在變,但現在,英吋已經有了一個明確的定義: 1 英吋精確地等於 2.54 釐米。因此,我們可以把 0.2 毫米當作單位長度,它就可以同時用於度量 1 英吋和 1 釐米: 1 英吋將正好等於 127 個單位長度, 1 釐米將正好等於 50 個單位長度。實際上, 0.1 毫米、 0.04 毫米 、 (0.2 / 3) 毫米也都可以用作 1 英吋和 1 釐米的公度單位,不過 0.2 毫米是最大的公度單位。
等等,我們怎麼知道 0.2 毫米是最大的公度單位?更一般地,任意給定兩條線段後,我們怎麼求出這兩條線段的最大公度單位呢?在《幾何原本》第七卷的命題 2 當中, Euclid 給出了一種求最大公度單位的通用算法,這就是後來所說的 Euclid 算法。這種方法其實非常直觀。假如我們要求線段 a 和線段 b 的最大公度單位,不妨假設 a 比 b 更長。如果 b 正好能度量 a ,那麼考慮到 b 當然也能度量它自身,因而 b 就是 a 和 b 的一個公度單位;如果 b 不能度量 a ,這說明 a 的長度等於 b 的某個整倍數,再加上一個零頭。我們不妨把這個零頭的長度記作 c 。如果有某條線段能夠同時度量 b 和 c ,那麼它顯然也就能度量 a 。也就是說,為了找到 a 和 b 的公度單位,我們只需要去尋找 b 和 c 的公度單位即可。怎樣找呢?我們故技重施,看看 c 是否能正好度量 b 。如果 c 正好能度量 b ,c 就是 b 和 c 的公度單位,從而也就是 a 和 b 的公度單位;如果 c 不能度量 b ,那看一看 b 被 c 度量之後剩餘的零頭,把它記作 d ,然後繼續用 d 度量 c ,並不斷這樣繼續下去,直到某一步沒有零頭了為止。

我們還是來看一個實際的例子吧。讓我們試著找出 690 和 2202 的公度單位。顯然, 1 是它們的一個公度單位, 2 也是它們的一個公度單位。我們希望用 Euclid 的算法求出它們的最大公度單位。首先,用 690 去度量 2202 ,結果發現 3 個 690 等於 2070 ,度量 2202 時會有一個大小為 132 的零頭。接下來,我們用 132 去度量 690 ,這將會產生一個 690 - 132 × 5 = 30 的零頭。用 30 去度量 132 ,仍然會有一個大小為 132 - 30 × 4 = 12 零頭。再用 12 去度量 30 ,零頭為 30 - 12 × 2 = 6 。最後,我們用 6 去度量 12 ,你會發現這回終於沒有零頭了。因此, 6 就是 6 和 12 的一個公度單位,從而是 12 和 30 的公度單位,從而是 30 和 132 的公度單位,從而是 132 和 690 的公度單位,從而是 690 和 2202 的公度單位。

我們不妨把 Euclid 算法對 a 和 b 進行這番折騰後得到的結果記作 x 。從上面的描述中我們看出, x 確實是 a 和 b 的公度單位。不過,它為什麼一定是最大的公度單位呢?為了說明這一點,下面我們來證明,事實上, a 和 b 的任意一個公度單位一定能夠度量 x ,從而不會超過 x 。如果某條長為 y 的線段能同時度量 a 和 b ,那麼注意到,它能度量 b 就意味著它能度量 b 的任意整倍數,要想讓它也能度量 a 的話,只需而且必需讓它能夠度量 c 。於是, y 也就能夠同時度量 b 和 c ,根據同樣的道理,這又可以推出 y 一定能度量 d ……因此,最後你會發現, y 一定能度量 x 。
用現在的話來講,求兩條線段的最大公度單位,實際上就是求兩個數的最大公約數——最大的能同時整除這兩個數的數。用現在的話來描述 Euclid 算法也會簡明得多:假設剛開始的兩個數是 a 和 b ,其中 a > b ,那麼把 a 除以 b 的餘數記作 c ,把 b 除以 c 的餘數記作 d ,c 除以 d 余 e , d 除以 e 余 f ,等等等等,不斷拿上一步的除數去除以上一步的餘數。直到某一次除法餘數為 0 了,那麼此時的除數就是最終結果。因此, Euclid 算法又有一個形象的名字,叫做「輾轉相除法」。
輾轉相除法的效率非常高,剛才大家已經看到了,計算 690 和 2202 的最大公約數時,我們依次得到的餘數是 132, 30, 12, 6 ,做第 5 次除法時就除盡了。實際上,我們可以大致估計出輾轉相除法的效率。第一次做除法時,我們是用 a 來除以 b ,把餘數記作 c 。如果 b 的值不超過 a 的一半,那麼 c 更不會超過 a 的一半(因為餘數小於除數);如果 b 的值超過了 a 的一半,那麼顯然 c 直接就等於 a - b ,同樣小於 a 的一半。因此,不管怎樣, c 都會小於 a 的一半。下一步輪到 b 除以 c ,根據同樣的道理,所得的餘數 d 會小於 b 的一半。接下來, e 將小於 c 的一半, f 將小於 d 的一半,等等等等。按照這種速度遞減下去的話,即使最開始的數是上百位的大數,不到 1000 次除法就會變成一位數(如果算法沒有提前結束的話),交給計算機來執行的話保證秒殺。用專業的說法就是,輾轉相除法的運算次數是對數級別的。
很長一段時間裡,古希臘人都認為,任意兩條線段都是可以公度的,我們只需要做一遍輾轉相除便能把這個公度單位給找出來。事實真的如此嗎?輾轉相除法有可能失效嗎?我們至少能想到一種可能:會不會有兩條長度關係非常特殊的線段,讓輾轉相除永遠達不到終止的條件,從而根本不能算出一個「最終結果」?注意,線段的長度不一定(也幾乎不可能)恰好是整數或者有限小數,它們往往是一些根本不能用有限的方式精確表示出來的數。考慮到這一點,兩條線段不可公度完全是有可能的。
為了讓兩條線段輾轉相除永遠除不盡,我們有一種絕妙的構造思路:讓線段 a 和 b 的比值恰好等於線段 b 和 c 的比值。這樣,輾轉相除一次後,兩數的關係又回到了起點。今後每一次輾轉相除,餘數總會佔據除數的某個相同的比例,於是永遠不會出現除盡的情況。不妨假設一種最為簡單的情況,即 a 最多只能包含一個 b 的長度,此時 c 等於 a - b 。解方程 a / b = b / (a - b) 可以得到 a : b = 1 : (√5 - 1) / 2 ,約等於一個大家非常熟悉的比值 1: 0.618 。於是我們馬上得出:成黃金比例的兩條線段是不可公度的。
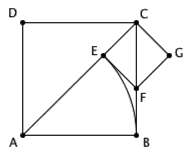
更典型的例子則是,正方形的邊長和對角線是不可公度的。讓我們畫個圖來說明這一點。如圖,我們試著用輾轉相除求出邊長 AB 和對角線 AC 的最大公度單位。按照規則,第一步我們應該用 AB 去度量 AC ,假設所得的零頭是 EC 。下一步,我們應該用 EC 去度量 AB ,或者說用 EC 去度量 BC (反正正方形各邊都相等)。讓我們以 EC 為邊作一個小正方形 CEFG ,容易看出 F 點將正好落在 BC 上,同時三角形 AEF 和三角形 ABF 將會由於 HL 全等。因此, EC = EF = BF 。注意到 BC 上已經有一段 BF 和 EC 是相等的了,因而我們用 EC 去度量 BC 所剩的零頭,也就相當於用 EC 去度量 FC 所剩的零頭。結果又回到了最初的局面——尋找正方形的邊長和對角線的公度單位。因而,輾轉相除永遠不會結束。線段 AB 的長度和線段 AC 的長度不能公度,它們處於兩個不同的世界中。
如果正方形 ABCD 的邊長 1 ,正方形的面積也就是 1 。從上圖中可以看到,若以對角線 AC 為邊做一個大正方形,它的面積就該是 2 。因而, AC 就應該是一個與自身相乘之後恰好等於 2 的數,我們通常把這個數記作 √2 。《幾何原本》的第十捲專門研究不可公度量,其中就有一段 1 和 √2 不可公度的證明,但所用的方法不是我們上面講的這種,而更接近於課本上的證明:設 √2 = p / q ,其中 p / q 已是最簡分數,但推著推著就發現,這將意味著 p 和 q 都是偶數,與最簡分數的假設矛盾。
用今天的話來講, 1 和 √2 不可公度,實際上相當於是說 √2 是無理數。因此,古希臘人發現了無理數,這確實當屬不爭的事實。奇怪的是,無理數的發現常常會幾乎毫無根據地歸功於一個史料記載嚴重不足的古希臘數學家 Hippasus 。根據各種不靠譜的描述, Hippasus 的發現觸犯了 Pythagoras (古希臘哲學家)的教條,最後被溺死在了海裡。
可公度線段和不可公度線段的概念與有理數和無理數的概念非常接近,我們甚至可以說明這兩個概念是等價的——它們之間有一種很巧妙的等價關係。注意到,即使 a 和 b 本身都是無理數, a 和 b 還是有可能被公度的,例如 a = √2 並且 b = 2 ‧ √2 的時候。不過,有一件事我們可以肯定: a 和 b 的比值一定是一個有理數。事實上,可以證明,線段 a 和 b 是可公度的,當且僅當 a / b 是一個有理數。線段 a 和 b 是可公度的,說明存在一個 c 以及兩個整數 m 和 n ,使得 a = m ‧ c ,並且 b = n ‧ c 。於是 a / b = (m ‧ c) / (n ‧ c) = m / n ,這是一個有理數。反過來,如果 a / b 是一個有理數,說明存在整數 m 和 n 使得 a / b = m / n ,等式變形後可得 a / m = b / n ,令這個商為 c ,那麼 c 就可以作為 a 和 b 的公度單位。
有時候,「是否可以公度」的說法甚至比「是否有理」更好一些,因為這是一個相對的概念,不是一個絕對的概念。當我們遇到生活當中的某個物理量時,我們絕不能指著它就說「這是一個有理的量」或者「這是一個無理的量」,我們只能說,以某某某(比如 1 釐米、 1 英吋、 0.2 毫米或者一支鉛筆的長度等等)作為單位來衡量時,這是一個有理的量或者無理的量。考慮到所選用的單位長度本身也是由另一個物理量定義出來的(比如 1 米被定義為光在真空中 1 秒走過的路程的 1 / 299792458 ),因而在討論一個物理量是否是有理數時,我們討論的其實是兩個物理量是否可以被公度。
(二)中國剩餘定理
如果兩個正整數的最大公約數為 1 ,我們就說這兩個數是互質的。這是一個非常重要的概念。如果 a 和 b 互質,這就意味著分數 a / b 已經不能再約分了,意味著 a × b 的棋盤的對角線不會經過中間的任何交叉點,意味著循環長度分別為 a 和 b 的兩個週期性事件一同上演,則新的循環長度最短為 a ‧ b 。
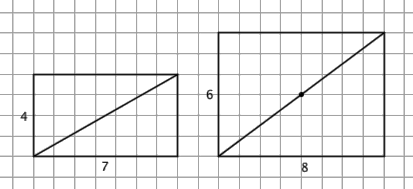
最後一點可能需要一些解釋。讓我們來舉些例子。假如有 1 路和 2 路兩種公交車,其中 1 路車每 6 分鐘一班,2 路車每 8 分鐘一班。如果你剛剛錯過兩路公交車同時出發的壯景,那麼下一次再遇到這樣的事情是多少分鐘之後呢?當然, 6 × 8 = 48 分鐘,這是一個正確的答案,此時 1 路公交車正好是第 8 班, 2 路公交車正好是第 6 班。不過,實際上,在第 24 分鐘就已經出現了兩車再次同發的情況了,此時 1 路車正好是第 4 班, 2 路車正好是第 3 班。但是,如果把例子中的 6 分鐘和 8 分鐘分別改成 4 分鐘和 7 分鐘,那麼要想等到兩車再次同發,等到第 4 × 7 = 28 分鐘是必需的。類似的,假如某一首歌的長度正好是 6 分鐘,另一首歌的長度正好是 8 分鐘,讓兩首歌各自循環播放, 6 × 8 = 48 分鐘之後你聽到的「合聲」將會重複,但實際上第 24 分鐘就已經開始重複了。但若兩首歌的長度分別是 4 分鐘和 7 分鐘,則必需到第 4 × 7 = 28 分鐘之後才有重複,循環現象不會提前發生。
究其原因,其實就是,對於任意兩個數,兩個數的乘積一定是它們的一個公倍數,但若這兩個數互質,則它們的乘積一定是它們的最小公倍數。事實上,我們還能證明一個更強的結論: a 和 b 的最大公約數和最小公倍數的乘積,一定等於 a 和 b 的乘積。在第四節中,我們會給出一個證明。
很多更複雜的數學現象也都跟互質有關。《孫子算經》卷下第二十六問:「今有物,不知其數。三、三數之,剩二;五、五數之,剩三;七、七數之,剩二。問物幾何?答曰:二十三。」翻譯過來,就是有一堆東西,三個三個數余 2 ,五個五個數余 3 ,七個七個數余 2 ,問這堆東西有多少個?《孫子算經》給出的答案是 23 個。當然,這個問題還有很多其他的解。由於 105 = 3 × 5 × 7 ,因而 105 這個數被 3 除、被 5 除、被 7 除都能除盡。所以,在 23 的基礎上額外加上一個 105 ,得到的 128 也是滿足要求的解。當然,我們還可以在 23 的基礎上加上 2 個 105 ,加上 3 個 105 ,等等,所得的數都滿足要求。除了形如 23 + 105n 的數以外,還有別的解嗎?沒有了。事實上,不管物體總數除以 3 的餘數、除以 5 的餘數以及除以 7 的餘數分別是多少,在 0 到 104 當中總存在唯一解;在這個解的基礎上再加上 105 的整倍數後,可以得到其他所有的正整數解。後人將其表述為「中國剩餘定理」:給出 m 個兩兩互質的整數,它們的乘積為 P ;假設有一個未知數 M ,如果我們已知 M 分別除以這 m 個數所得的餘數,那麼在 0 到 P - 1 的範圍內,我們可以唯一地確定這個 M 。這可以看作是 M 的一個特解。其他所有滿足要求的 M ,則正好是那些除以 P 之後餘數等於這個特解的數。注意,除數互質的條件是必需的,否則結論就不成立了。比如說,在 0 到 7 的範圍內,除以 4 余 1 並且除以 2 也余 1 的數有 2 個,除以 4 余 1 並且除以 2 余 0 的數則一個也沒有。
從某種角度來說,中國剩餘定理幾乎是顯然的。讓我們以兩個除數的情況為例,來說明中國剩餘定理背後的直覺吧。假設兩個除數分別是 4 和 7 。下表顯示的就是各自然數除以 4 和除以 7 的餘數情況,其中 x mod y 表示 x 除以 y 的餘數,這個記號後面還會用到。
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| i mod 4 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 |
| i mod 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 0 | 1 | 2 | 3 | 4 | 5 |
| i | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 |
| i mod 4 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 |
| i mod 7 | 6 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 0 | 1 | 2 | 3 | 4 |
i mod 4 的值顯然是以 4 為週期在循環, i mod 7 的值顯然是以 7 為週期在循環。由於 4 和 7 是互質的,它們的最小公倍數是 4 × 7 = 28 ,因而 (i mod 4, i mod 7) 的循環週期是 28 ,不會更短。因此,當 i 從 0 增加到 27 時, (i mod 4, i mod 7) 的值始終沒有出現重複。但是, (i mod 4, i mod 7) 也就只有 4 × 7 = 28 種不同的取值,因而它們正好既無重複又無遺漏地分給了 0 到 27 之間的數。這說明,每個特定的餘數組合都在前 28 項中出現過,並且都只出現過一次。在此之後,餘數組合將產生長度為 28 的循環,於是每個特定的餘數組合都將會以 28 為週期重複出現。這正是中國剩餘定理的內容。
中國剩餘定理有很多漂亮的應用,這裡我想說一個我最喜歡的。設想這樣一個場景:總部打算把一份秘密文件發送給 5 名特工,但直接把文件原封不動地發給每個人,很難保障安全性。萬一有特工背叛或者被捕,把秘密洩露給了敵人怎麼辦?於是就有了電影和小說中經常出現的情節:把絕密文件拆成 5 份, 5 名特工各自只持有文件的 1/5 。不過,原來的問題並沒有徹底解決,我們只能祈禱壞人竊取到的並不是最關鍵的文件片段。因此,更好的做法是對原文件進行加密,每名特工只持有密碼的 1/5 ,這 5 名特工需要同時在場才能獲取文件全文。但這也有一個隱患:如果真的有特工被抓了,當壞人們發現只拿到其中一份密碼沒有任何用處的同時,特工們也會因為少一份密碼無法解開全文而煩惱。此時,你或許會想,是否有什麼辦法能夠讓特工們仍然可以恢復原文,即使一部分特工被抓住了?換句話說,有沒有什麼密文發佈方式,使得只要 5 個人中半數以上的人在場就可以解開絕密文件?這樣的話,壞人必須要能操縱半數以上的特工才可能對秘密文件造成實質性的影響。這種秘密共享方式被稱為 (3, 5) 門限方案,意即 5 個人中至少 3 人在場才能解開密文。
利用中國剩餘定理,我們可以得到一種巧妙的方案。回想中國剩餘定理的內容:給定 m 個兩兩互質的整數,它們的乘積為 P ;假設有一個未知數 M ,如果我們已知 M 分別除以這 m 個數所得的餘數,那麼在 0 到 P - 1 的範圍內,我們可以唯一地確定這個 M 。我們可以想辦法構造這樣一種情況, n 個數之中任意 m 個的乘積都比 M 大,但是任意 m - 1 個數的乘積就比 M 小。這樣,任意 m 個除數就能唯一地確定 M ,但 m - 1 個數就不足以求出 M 來。 Mignotte 門限方案就用到了這樣一個思路。我們選取 n 個兩兩互質的數,使得最小的 m 個數的乘積比最大的 m - 1 個數的乘積還大。例如,在 (3, 5) 門限方案中,我們可以取 53 、 59 、 64 、 67 、 71 這 5 個數,前面 3 個數乘起來得 200128 ,而後面兩個數相乘才得 4757 。我們把文件的密碼設為一個 4757 和 200128 之間的整數,比如 123456 。分別算出 123456 除以上面那 5 個數的餘數,得到 19 、 28 、 0 、 42 、 58 。然後,把 (53, 19) 、 (59, 28) 、 (64, 0) 、 (67, 42) 、 (71, 58) 分別告訴 5 名特工,也就是說特工 1 只知道密碼除以 53 余 19 ,特工 2 只知道密碼除以 59 余 28 ,等等。這樣,根據中國剩餘定理,任意 3 名特工碰頭後就可以唯一地確定出 123456 ,但根據 2 名特工手中的信息只能得到成百上千個不定解。例如,假設我們知道了 x 除以 59 余 28 ,也知道了 x 除以 67 余 42 ,那麼我們只能確定在 0 和 59 × 67 - 1 之間有一個解 913 ,在 913 的基礎上加上 59 × 67 的整倍數,可以得到其他滿足要求的 x ,而真正的 M 則可以是其中的任意一個數。
不過,為了讓 Mignotte 門限方案真正可行,我們還需要一種根據餘數信息反推出 M 的方法。換句話說,我們需要有一種通用的方法,能夠回答《孫子算經》中提出的那個問題。我們會在下一節中講到。
(三)擴展的輾轉相除
中國剩餘定理是一個很基本的定理。很多數學現象都可以用中國剩餘定理來解釋。背九九乘法口訣表時,你或許會發現,寫下 3 × 1, 3 × 2, ..., 3 × 9 ,它們的個位數正好遍歷了 1 到 9 所有的情況。 7 的倍數、 9 的倍數也是如此,但 2 、 4 、 5 、 6 、 8 就不行。 3 、 7 、 9 這三個數究竟有什麼特別的地方呢?秘密就在於, 3 、 7 、 9 都是和 10 互質的。比如說 3 ,由於 3 和 10 是互質的,那麼根據中國剩餘定理,在 0 到 29 之間一定有這樣一個數,它除以 3 余 0 ,並且除以 10 余 1 。它將會是 3 的某個整倍數,並且個位為 1 。同樣的,在 0 到 29 之間也一定有一個 3 的整倍數,它的個位是 2 ;在 0 到 29 之間也一定有一個 3 的整倍數,它的個位是 3 ……而在 0 到 29 之間,除掉 0 以外, 3 的整倍數正好有 9 個,於是它們的末位就正好既無重複又無遺漏地取遍了 1 到 9 所有的數字。
這表明,如果 a 和 n 互質,那麼 a ‧ x mod n = 1 、 a ‧ x mod n = 2 等所有方程都是有解的。 18 世紀的法國數學家 Étienne Bézout 曾經證明了一個基本上與此等價的定理,這裡我們姑且把它叫做「 Bézout 定理」。事實上,我們不但知道上述方程是有解的,還能求出所有滿足要求的解來。
我們不妨花點時間,把方程 a ‧ x mod n = b 和中國剩餘定理的關係再理一下。尋找方程 a ‧ x mod n = b 的解,相當於尋找一個 a 的倍數使得它除以 n 余 b ,或者說是尋找一個數 M 同時滿足 M mod a = 0 且 M mod n = b 。如果 a 和 n 是互質的,那麼根據中國剩餘定理,這樣的 M 一定存在,並且找到一個這樣的 M 之後,在它的基礎上加減 a ‧ n 的整倍數,可以得到所有滿足要求的 M 。因此,為瞭解出方程 a ‧ x mod n = b 的所有解,我們也只需要解出方程的某個特解就行了。假如我們找到了方程 a ‧ x mod n = b 中 x 的一個解,在這個解的基礎上加上或減去 n 的倍數(相當於在整個被除數 a ‧ x 的基礎上加上或者減去 a ‧ n 的倍數,這裡的 a ‧ x 就是前面所說的 M ),就能得到所有的解了。
更妙的是,我們其實只需要考慮形如 a ‧ x mod n = 1 的方程。因為,如果能解出這樣的方程, a ‧ x mod n = 2 、 a ‧ x mod n = 3 也都自動地獲解了。假如 a ‧ x mod n = 1 有一個解 x = 100 ,由於 100 個 a 除以 n 余 1 ,自然 200 個 a 除以 n 就余 2 , 300 個 a 除以 n 就余 3 ,等等,等式右邊餘數不為 1 的方程也都解開了。
讓我們嘗試求解 115x mod 367 = 1 。注意,由於 115 和 367 是互質的,因此方程確實有解。我們解方程的基本思路是,不斷尋找 115 的某個倍數以及 367 的某個倍數,使得它們之間的差越來越小,直到最終變為 1 。由於 367 除以 115 得 3 ,余 22 ,因而 3 個 115 只比 367 少 22 。於是, 15 個 115 就要比 5 個 367 少 110 ,從而 16 個 115 就會比 5 個 367 多 5 。好了,真正巧妙的就在這裡了: 16 個 115 比 5 個 367 多 5 ,但 3 個 115 比 1 個 367 少 22 ,兩者結合起來,我們便能找到 115 的某個倍數和 367 的某個倍數,它們只相差 2 : 16 個 115 比 5 個 367 多 5 ,說明 64 個 115 比 20 個 367 多 20 ,又考慮到 3 個 115 比 1 個 367 少 22 ,於是 67 個 115 只比 21 個 367 少 2 。現在,結合「少 2 」和「多 5 」兩個式子,我們就能把差距縮小到 1 了: 67 個 115 比 21 個 367 少 2 ,說明 134 個 115 比 42 個 367 少 4 ,而 16 個 115 比 5 個 367 多 5 ,於是 150 個 115 比 47 個 367 多 1 。這樣,我們就解出了一個滿足 115x mod 367 = 1 的 x ,即 x = 150 。大家會發現,在求解過程,我們相當於對 115 和 367 做了一遍輾轉相除:我們不斷給出 115 的某個倍數和 367 的某個倍數,通過輾轉對比最近的兩個結果,讓它們的差距從「少 22 」縮小到「多 5 」,再到「少 2 」、「多 1 」,其中 22, 5, 2, 1 這幾個數正是用輾轉相除法求 115 和 367 的最大公約數時將會經歷的數。因而,算法的步驟數仍然是對數級別的,即使面對上百位上千位的大數,計算機也毫無壓力。這種求解方程 a ‧ x mod n = b 的算法就叫做「擴展的輾轉相除法」。
注意,整個算法有時也會以「少 1 」的形式告終。例如,用此方法求解 128x mod 367 = 1 時,最後會得出 43 個 128 比 15 個 367 少 1 。這下怎麼辦呢?很簡單, 43 個 128 比 15 個 367 少 1 ,但是 367 個 128 顯然等於 128 個 367 ,對比兩個式子可知, 324 個 128 就會比 113 個 367 多 1 了,於是得到 x = 324 。
最後還有一個問題:我們最終總能到達「多 1 」或者「少 1 」,這正是因為一開始的兩個數是互質的。如果方程 a ‧ x mod n = b 當中 a 和 n 不互質,它們的最大公約數是 d > 1 ,那麼在 a 和 n 之間做輾轉相除時,算到 d 就直接終止了。自然,擴展的輾轉相除也將在到達「多 1 」或者「少 1 」之前提前結束。那怎麼辦呢?我們有一種巧妙的處理方法:以 d 為單位重新去度量 a 和 n (或者說讓 a 和 n 都除以 d ),問題就變成我們熟悉的情況了。讓我們來舉個例子吧。假如我們要解方程 24 ‧ x mod 42 = 30 ,為了方便後面的解釋,我們來給這個方程編造一個背景:說一盒雞蛋 24 個,那麼買多少盒雞蛋,才能讓所有的雞蛋 42 個 42 個地數最後正好能余 30 個?我們發現 24 和 42 不是互質的,擴展的輾轉相除似乎就沒有用了。不過沒關係。我們找出 24 和 42 的最大公約數,發現它們的最大公約數是 6 。現在,讓 24 和 42 都來除以 6 ,分別得到 4 和 7 。由於 6 已經是 24 和 42 的公約數中最大的了,因此把 24 和 42 當中的 6 除掉後,剩下的 4 和 7 就不再有大於 1 的公約數,從而就是互質的了。好了,現在我們把題目改編一下,把每 6 個雞蛋視為一個新的單位量,比如說「 1 把」。記住, 1 把雞蛋就是 6 個雞蛋。於是,原問題就變成了,每個盒子能裝 4 把雞蛋,那麼買多少盒雞蛋,才能讓所有的雞蛋 7 把 7 把地數,最後正好會余 5 把?於是,方程就變成了 4 ‧ x mod 7 = 5 。由於此時 4 和 7 是互質的了,因而套用擴展的輾轉相除法,此方程一定有解。可以解出特解 x = 3 ,在它的基礎上加減 7 的整倍數,可以得到其他所有滿足要求的 x 。這就是改編之後的問題的解。但是,雖說我們對原題做了「改編」,題目內容本身卻完全沒變,連數值都沒變,只不過換了一種說法。改編後的題目裡需要買 3 盒雞蛋,改編前的題目裡當然也是要買 3 盒雞蛋。 x = 3 ,以及所有形如 3 + 7n 的數,也都是原方程的解。
大家或許已經看到了,我們成功地找到了 24 ‧ x mod 42 = 30 的解,依賴於一個巧合: 24 和 42 的最大公約數 6 ,正好也是 30 的約數。因此,改用「把」作單位重新敘述問題,正好最後的「余 30 個」變成了「余 5 把」,依舊是一個整數。如果原方程是 24 ‧ x mod 42 = 31 的話,我們就沒有那麼走運了,問題將變成「買多少盒才能讓最後數完余 5 又 1/6 把」。這怎麼可能呢?我們是整把整把地買,整把整把地數,當然餘數也是整把整把的。因此,方程 24 ‧ x mod 42 = 31 顯然無解。
綜上所述,如果關於 x 的方程 a ‧ x mod n = b 當中的 a 和 n 不互質,那麼求出 a 和 n 的最大公約數 d 。如果 b 恰好是 d 的整倍數,那麼把方程中的 a 、 n 、 b 全都除以 d ,新的 a 和 n 就互質了,新的 b 也恰好為整數,用擴展的輾轉相除求解新方程,得到的解也就是原方程的解。但若 b 不是 d 的整倍數,則方程無解。
擴展的輾轉相除法有很多應用,其中一個有趣的應用就是大家小時候肯定見過的「倒水問題」。假如你有一個 3 升的容器和一個 5 升的容器(以及充足的水源),如何精確地取出 4 升的水來?為了敘述簡便,我們不妨把 3 升的容器和 5 升的容器分別記作容器 A 和容器 B 。一種解法如下:
1. 將 A 裝滿,此時 A 中的水為 3 升, B 中的水為 0 升;
2. 將 A 裡的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 3 升;
3. 將 A 裝滿,此時 A 中的水為 3 升, B 中的水為 3 升;
4. 將 A 裡的水倒入 B 直到把 B 裝滿,此時 A 中的水為 1 升, B 中的水為 5 升;
5. 將 B 裡的水全部倒掉,此時 A 中的水為 1 升, B 中的水為 0 升;
6. 將 A 裡剩餘的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 1 升;
7. 將 A 裝滿,此時 A 中的水為 3 升, B 中的水為 1 升;
8. 將 A 裡的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 4 升;
2. 將 A 裡的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 3 升;
3. 將 A 裝滿,此時 A 中的水為 3 升, B 中的水為 3 升;
4. 將 A 裡的水倒入 B 直到把 B 裝滿,此時 A 中的水為 1 升, B 中的水為 5 升;
5. 將 B 裡的水全部倒掉,此時 A 中的水為 1 升, B 中的水為 0 升;
6. 將 A 裡剩餘的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 1 升;
7. 將 A 裝滿,此時 A 中的水為 3 升, B 中的水為 1 升;
8. 將 A 裡的水全部倒入 B ,此時 A 中的水為 0 升, B 中的水為 4 升;
這樣,我們就得到 4 升的水了。顯然,這類問題可以編出無窮多個來,比如能否用 7 升的水杯和 13 升的水杯量出 5 升的水,能否又用 9 升的水杯和 15 升的水杯量出 10 升的水,等等。這樣的問題有什麼萬能解法嗎?有!注意到,前面用 3 升的水杯和 5 升的水杯量出 4 升的水,看似複雜的步驟可以簡單地概括為:不斷將整杯整杯的 A 往 B 裡倒,期間只要 B 被裝滿就把 B 倒空。由於 3 × 3 mod 5 = 4 ,因而把 3 杯的 A 全部倒進 B 裡,並且每裝滿一個 B 就把水倒掉, B 裡面正好會剩下 4 升的水。類似地,用容積分別為 a 和 b 的水杯量出體積為 c 的水,實際上相當於解方程 a ‧ x mod b = c 。如果 c 是 a 和 b 的最大公約數,或者能被它們的最大公約數整除,用擴展的輾轉相除便能求出 x ,得到對應的量水方案。特別地,如果兩個水杯的容積互質,問題將保證有解。如果 c 不能被 a 和 b 的最大公約數整除,方程就沒有解了,怎麼辦?不用著急,因為很顯然,此時問題正好也沒有解。比方說 9 和 15 都是 3 的倍數,那我們就把每 3 升的水視作一個單位,於是你會發現,在 9 升和 15 升之間加加減減,倒來倒去,得到的量永遠只能在 3 的倍數當中轉,絕不可能弄出 10 升的水來。這樣一來,我們就給出了問題有解無解的判斷方法,以及在有解時生成一種合法解的方法,從而完美地解決了倒水問題。
最後,讓我們把上一節留下的一點懸唸給補完:怎樣求解《孫子算經》中的「今有物,不知其數」一題。已知有一堆東西,三個三個數余 2 ,五個五個數余 3 ,七個七個數余 2 ,問這堆東西有多少個?根據中國剩餘定理,由於除數 3 、 5 、 7 兩兩互質,因而在 0 到 104 之間,該問題有唯一的答案。我們求解的基本思路就是,依次找出滿足每個條件,但是又不會破壞掉其他條件的數。我們首先要尋找一個數,它既是 5 的倍數,又是 7 的倍數,同時除以 3 正好余 2 。這相當於是在問, 35 的多少倍除以 3 將會余 2 。於是,我們利用擴展的輾轉相除法求解方程 35x mod 3 = 2 。這個方程是一定有解的,因為 5 和 3 、 7 和 3 都是互質的,從而 5 × 7 和 3 也是互質的(到了下一節,這一點會變得很顯然)。解這個方程可得 x = 1 。於是, 35 就是我們要找到的數。第二步,是尋找這麼一個數,它既是 3 的倍數,又是 7 的倍數,同時除以 5 余 3 。這相當於求解方程 21x mod 5 = 3 ,根據和剛才相同的道理,這個方程一定有解。可以解得 x = 3 ,因此我們要找的數就是 63 。最後,我們需要尋找一個數,它能同時被 3 和 5 整除,但被 7 除余 2 。這相當於求解方程 15x mod 7 = 2 ,解得 x = 2 。我們想要找的數就是 30 。現在,如果我們把 35 、 63 和 30 這三個數加在一起會怎麼樣?它將會同時滿足題目當中的三個條件!它滿足「三個三個數余 2 」,因為 35 除以 3 是余 2 的,而後面兩個數都是 3 的整倍數,所以加在一起後除以 3 仍然余 2 。類似地,它滿足「五個五個數余 3 」,因為 63 除以 5 余 3 ,另外兩個數都是 5 的倍數。類似地,它也滿足「七個七個數余 2 」,因而它就是原問題的一個解。你可以驗證一下, 35 + 63 + 30 = 128 ,它確實滿足題目的所有要求!為了得出一個 0 到 104 之間的解,我們在 128 的基礎上減去一個 105 ,於是正好得到《孫子算經》當中給出的答案, 23 。
已知 M 除以 m 個兩兩互質的數之後所得的餘數,利用類似的方法總能反解出 M 來。至此,我們也就完成了 Mignotte 秘密共享方案的最後一環。
(四)Fermat 小定理
很多自然數都可以被分解成一些更小的數的乘積,例如 12 可以被分成 4 乘以 3 ,其中 4 還可以繼續地被分成 2 乘以 2 ,因而我們可以把 12 寫作 2 × 2 × 3 。此時, 2 和 3 都不能再繼續分解了,它們是最基本、最純淨的數。我們就把這樣的數叫做「質數」或者「素數」。同樣地, 2 、 3 、 5 、 7 、 11 、 13 等等都是不可分解的,它們也都是質數。它們是自然數的構件,是自然數世界的基本元素。 12 是由兩個 2 和一個 3 組成的,正如水分子是由兩個氫原子和一個氧原子組成的一樣。只不過,和化學世界不同的是,自然數世界裡的基本元素是無限的——質數有無窮多個。
關於為什麼質數有無窮多個,古希臘的 Euclid 有一個非常漂亮的證明。假設質數隻有有限個,其中最大的那個質數為 p 。現在,把所有的質數全部乘起來,再加上 1 ,得到一個新的數 N 。也就是說, N 等於 2 ‧ 3 ‧ 5 ‧ 7 ‧ … ‧ p + 1 。注意到, N 除以每一個質數都會余 1 ,比如 N 除以 2 就會商 3 ‧ 5 ‧ 7 ‧ … ‧ p 余 1 , N 除以 3 就會商 2 ‧ 5 ‧ 7 ‧ … ‧ p 余 1 ,等等。這意味著, N 不能被任何一個質數整除,換句話說 N 是不能被分解的,它本身就是質數。然而這也不對,因為 p 已經是最大的質數了,於是產生了矛盾。這說明,我們剛開始的假設是錯的,質數應該有無窮多個。需要額外說明的一點是,這個證明容易讓人產生一個誤解,即把頭 n 個質數乘起來再加 1 ,總能產生一個新的質數。這是不對的,因為既然我們無法把全部質數都乘起來,那麼所得的數就有可能是由那些我們沒有乘進去的質數構成的,比如 2 ‧ 3 ‧ 5 ‧ 7 ‧ 11 ‧ 13 + 1 = 30031 ,它可以被分解成 59 × 509 。
從古希臘時代開始,人們就近乎瘋狂地想要認識自然數的本質規律。組成自然數的基本元素自然地就成為了一個絕佳的突破口,於是對質數的研究成為了探索自然數世界的一個永久的話題。這就是我們今天所說的「數論」。
用質數理論來研究數,真的會非常方便。 a 是 b 的倍數(或者說 a 能被 b 整除, b 是 a 的約數),意思就是 a 擁有 b 所含的每一種質數,而且個數不會更少。我們舉個例子吧,比如說 b = 12 ,它可以被分解成 2 × 2 × 3 , a = 180 ,可以被分解成 2 × 2 × 3 × 3 × 5 。 b 裡面有兩個 2 ,這不稀罕, a 裡面也有兩個 2 ; b 裡面有一個 3 ,這也沒什麼, a 裡面有兩個 3 呢。況且, a 裡面還包含有 b 沒有的質數, 5 。對於每一種質數, b 裡面所含的個數都比不過 a ,這其實就表明了 b 就是 a 的約數。
現在,假設 a = 36 = 2 × 2 × 3 × 3 , b = 120 = 2 × 2 × 2 × 3 × 5 。那麼, a 和 b 的最大公約數是多少?我們可以依次考察,最大公約數里面可以包含哪些質數,每個質數都能有多少個。這個最大公約數最多可以包含多少個質數 2 ?顯然最多只能包含兩個,否則它就不能整除 a 了;這個最大公約數最多可以包含多少個質數 3 ?顯然最多只能包含一個,否則它就不能整除 b 了;這個最大公約數最多可以包含多少個質數 5 ?顯然一個都不能有,否則它就不能整除 a 了。因此, a 和 b 的最大公約數就是 2 × 2 × 3 = 12 。
在構造 a 和 b 的最小公倍數時,我們希望每種質數在數量足夠的前提下越少越好。為了讓這個數既是 a 的倍數,又是 b 的倍數,三個 2 是必需的;為了讓這個數既是 a 的倍數,又是 b 的倍數,兩個 3 是必需的;為了讓這個數既是 a 的倍數,又是 b 的倍數,那一個 5 也是必不可少的。因此, a 和 b 的最小公倍數就是 2 × 2 × 2 × 3 × 3 × 5 = 360 。
你會發現, 12 × 360 = 36 × 120 ,最大公約數乘以最小公倍數正好等於原來兩數的乘積。這其實並不奇怪。在最大公約數里面,每種質數各有多少個,取決於 a 和 b 當中誰所含的這種質數更少一些。在最小公倍數里面,每種質數各有多少個,取決於 a 和 b 當中誰所含的這種質數更多一些。因此,對於每一種質數而言,最大公約數和最小公倍數里面一共包含了多少個這種質數, a 和 b 裡面也就一共包含了多少個這種質數。最大公約數和最小公倍數乘在一起,也就相當於是把 a 和 b 各自所包含的質數都乘了個遍,自然也就等於 a 與 b 的乘積了。這立即帶來了我們熟悉的推論:如果兩數互質,這兩數的乘積就是它們的最小公倍數。
第三節裡,我們曾說到,「因為 5 和 3 、 7 和 3 都是互質的,從而 5 × 7 和 3 也是互質的」。利用質數的觀點,這很容易解釋。兩個數互質,相當於是說這兩個數不包含任何相同的質數。如果 a 與 c 互質, b 與 c 互質,顯然 a ‧ b 也與 c 互質。另外一個值得注意的結論是,如果 a 和 b 是兩個不同的質數,則這兩個數顯然就直接互質了。事實上,只要知道了 a 是質數,並且 a 不能整除 b ,那麼不管 b 是不是質數,我們也都能確定 a 和 b 是互質的。我們後面會用到這些結論。
在很多場合中,質數都扮演著重要的角色。 1640 年,法國業餘數學家 Pierre de Fermat (通常譯作「費馬」)發現,如果 n 是一個質數的話,那麼對於任意一個數 a , a 的 n 次方減去 a 之後都將是 n 的倍數。例如, 7 是一個質數,於是 27 - 2 、 37 - 3 , 47 - 4 ,甚至 1007 - 100 ,統統都能被 7 整除。但 15 不是質數(它可以被分解為 3 × 5 ),於是 a15 - a 除以 15 之後就可能會出現五花八門的餘數了。這個規律在數論研究中是如此基本如此重要,以至於它有一個專門的名字—— Fermat 小定理。作為一個業餘數學家, Fermat 發現了很多數論中精彩的結論, Fermat 「小」定理只是其中之一。雖然與本文無關,但有一點不得不提:以 Fermat 的名字命名的東西里,最著名的要數 Fermat 大定理了(其實譯作「 Fermat 最終定理」更貼切)。如果你沒聽說過,上網查查,或者看看相關的書籍。千萬不要錯過與此相關的一系列激動人心的故事。
言歸正傳。 Fermat 小定理有一個非常精彩的證明。我們不妨以「 37 - 3 能被 7 整除」為例進行說明,稍後你會發現,對於其他的情況,道理是一樣的。首先,讓我來解釋一下「循環移位」的意思。想像一個由若干字符所組成的字符串,在一塊大小剛好合適的 LED 屏幕上滾動顯示。比方說, HELLOWORLD 就是一個 10 位的字符串,而我們的 LED 屏幕不多不少正好容納 10 個字符。剛開始,屏幕上顯示 HELLOWORLD 。下一刻,屏幕上的字母 H 將會移出屏幕,但又會從屏幕右邊移進來,於是屏幕變成了 ELLOWORLDH 。下一刻,屏幕變成了 LLOWORLDHE ,再下一刻又變成了 LOWORLDHEL 。移動到第 10 次,屏幕又會回到 HELLOWORLD 。在此過程中,屏幕上曾經顯示過的 ELLOWORLDH, LLOWORLDHE, LOWORLDHEL, ... ,都是由初始的字符串 HELLOWORLD 通過「循環移位」得來的。現在,考慮所有僅由 A 、 B 、 C 三個字符組成的長度為 7 的字符串,它們一共有 37 個。如果某個字符串循環移位後可以得到另一個字符串,我們就認為這兩個字符串屬於同一組字符串。比如說, ABBCCCC 和 CCCABBC 就屬於同一組字符串,並且該組內還有其他 5 個字符串。於是,在所有 37 個字符串當中,除了 AAAAAAA 、 BBBBBBB 、 CCCCCCC 這三個特殊的字符串以外,其他所有的字符串正好都是每 7 個一組。這說明, 37 - 3 能被 7 整除。
在這個證明過程中,「 7 是質數」這個條件用到哪裡去了?仔細想想你會發現,正因為 7 是質數,所以每一組裡才恰好有 7 個字符串。如果字符串的長度不是 7 而是 15 的話,有些組裡將會只含 3 個或者 5 個字符串。比方說, ABCABCABCABCABC 所在的組裡就只有 3 個字符串,循環移動 3 個字符後,字符串將會和原來重合。
Fermat 小定理有一個等價的表述:如果 n 是一個質數的話,那麼對於任意一個數 a ,隨著 i 的增加, a 的 i 次方除以 n 的餘數將會呈現出長度為 n - 1 的週期性(下表所示的是 a = 3 、 n = 7 的情況)。這是因為,根據前面的結論, an 與 a 的差能夠被 n 整除,這說明 an 和 a 分別都除以 n 之後將會擁有相同的餘數。這表明,依次計算 a 的 1 次方、 2 次方、 3 次方除以 n 的餘數,算到 a 的 n 次方時,餘數將會變得和最開始相同。另一方面, ai 除以 n 的餘數,完全由 ai-1 除以 n 的餘數決定。比方說,假如我們已經知道 33 除以 7 等於 3 余 6 ,這表明 33 裡包含 3 個 7 以及 1 個 6 ;因此, 34 裡就包含 9 個 7 以及 3 個 6 ,或者說 9 個 7 以及 1 個 18 。為了得到 34 除以 7 的餘數,只需要看看 18 除以 7 余多少就行了。可見,要想算出 ai-1 ‧ a 除以 n 的餘數,我們不需要完整地知道 ai-1 的值,只需要知道 ai-1 除以 n 的餘數就可以了。反正最後都要對乘積取餘,相乘之前事先對乘數取餘不會對結果造成影響(記住這一點,後面我們還會多次用到)。既然第 n 個餘數和第 1 個餘數相同,而餘數序列的每一項都由上一項決定,那麼第 n + 1 個、第 n + 2 個餘數也都會跟著和第 2 個、第 3 個餘數相同,餘數序列從此處開始重複,形成長為 n - 1 的週期。
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 3i | 3 | 9 | 27 | 81 | 243 | 729 | 2187 | 6561 | 19683 | 59049 | 177147 | 531441 | 1594323 | 4782969 | 14348907 |
| 3i mod 7 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 |
需要注意的是, n - 1 並不見得是最小的週期。下表所示的是 2i 除以 7 的餘數情況,餘數序列確實存在長度為 6 的週期現象,但實際上它有一個更小的週期, 3 。
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 2i | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 |
| 2i mod 7 | 2 | 4 | 1 | 2 | 4 | 1 | 2 | 4 | 1 | 2 | 4 | 1 | 2 | 4 | 1 |
那麼,如果除數 n 不是質數,而是兩個質數的乘積(比如 35 ),週期的長度又會怎樣呢?讓我們試著看看, 3i 除以 35 的餘數有什麼規律吧。注意到 5 和 7 是兩個不同的質數,因而它們是互質的。根據中國剩餘定理,一個數除以 35 的餘數就可以唯一地由它除以 5 的餘數和除以 7 的餘數確定出來。因而,為了研究 3i 除以 35 的餘數,我們只需要觀察 (3i mod 5, 3i mod 7) 即可。由 Fermat 小定理可知,數列 3i mod 5 有一個長為 4 的週期,數列 3i mod 7 有一個長為 6 的週期。 4 和 6 的最小公倍數是 12 ,因此 (3i mod 5, 3imod 7) 存在一個長為 12 的週期。到了 i = 13 時, (3i mod 5, 3i mod 7) 將會和最開始重複,於是 3i 除以 35 的餘數將從此處開始發生循環。
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 3i mod 5 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 |
| 3i mod 7 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 |
| 3i mod 35 | 3 | 9 | 27 | 11 | 33 | 29 | 17 | 16 | 13 | 4 | 12 | 1 | 3 | 9 | 27 | 11 | 33 | 29 | 17 | 16 | 13 | 4 |
| i | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
| 3i mod 5 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 1 |
| 3i mod 7 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 | 6 | 4 | 5 | 1 | 3 | 2 |
| 3i mod 35 | 12 | 1 | 3 | 9 | 27 | 11 | 33 | 29 | 17 | 16 | 13 | 4 | 12 | 1 | 3 | 9 | 27 | 11 | 33 | 29 | 17 | 16 |
類似地,假如某個整數 n 等於兩個質數 p 、 q 的乘積,那麼對於任意一個整數 a ,寫出 ai 依次除以 n 所得的餘數序列, p - 1 和 q - 1 的最小公倍數將成為該序列的一個週期。事實上, p - 1 和 q - 1 的任意一個公倍數,比如表達起來最方便的 (p - 1) × (q - 1) ,也將成為該序列的一個週期。這個規律可以用來解釋很多數學現象。例如,大家可能早就注意過,任何一個數的乘方,其個位數都會呈現長度為 4 的週期(這包括了週期為 1 和週期為 2 的情況)。其實這就是因為, 10 等於 2 和 5 這兩個質數的乘積,而 (2 - 1) × (5 - 1) = 4,因此任意一個數的乘方除以 10 的餘數序列都將會產生長為 4 的週期。
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 3i | 3 | 9 | 27 | 81 | 243 | 729 | 2187 | 6561 | 19683 | 59049 |
| 3i的個位 | 3 | 9 | 7 | 1 | 3 | 9 | 7 | 1 | 3 | 9 |
| 4i | 4 | 16 | 64 | 256 | 1024 | 4096 | 16384 | 65536 | 262144 | 1048576 |
| 4i的個位 | 4 | 6 | 4 | 6 | 4 | 6 | 4 | 6 | 4 | 6 |
| 5i | 5 | 25 | 125 | 625 | 3125 | 15625 | 78125 | 390625 | 1953125 | 9765625 |
| 5i的個位 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
1736 年,瑞士大數學家 Leonhard Euler (通常譯作「歐拉」)對此做過進一步研究,討論了當 n 是更複雜的數時推導餘數序列循環週期的方法,得到了一個非常漂亮的結果:在 1 到 n 的範圍內有多少個數和 n 互質(包括 1 在內), a 的 i 次方除以 n 的餘數序列就會有一個多長的週期。這個經典的結論就叫做「 Euler 定理」。作為歷史上最高產的數學家之一, Euler 的一生當中發現的定理實在是太多了。為了把上述定理和其他的「 Euler 定理」區別開來,有時也稱它為「 Fermat - Euler 定理」。這是一個非常深刻的定理,它有一些非常具有啟發性的證明方法。考慮到在後文的講解中這個定理不是必需的,因此這裡就不詳說了。
這些東西有什麼用呢?沒有什麼用。幾千年來,數論一直沒有任何實際應用,數學家們研究數論的動力完全來源於數字本身的魅力。不過,到了 1970 年左右,情況有了戲劇性的變化。
有的朋友可能要說了,你怎麼賴皮呢,「沒有任何實際應用」,那剛才的 Mignotte 秘密共享方案算什麼?其實, Mignotte 秘密共享方案已經是很後來的事了。秘密共享本來遠沒那麼複雜,為了使得只要 5 個人中半數以上的人在場就可以解開絕密文件,總部可以把絕密文件鎖進一個特殊的機械裝置裡,裝置上有三個一模一樣的鎖孔,並配有 5 把完全相同且不可複製的鑰匙。只有把其中任意 3 把鑰匙同時插進鑰匙孔並一起轉動,才能打開整個裝置。把 5 把鑰匙分發給 5 名特工,目的就直接達到了。因而,通常情況下我們並不需要動用 Mignotte 秘密共享方案。那麼,利用中國剩餘定理費盡周折弄出的 Mignotte 秘密共享方案,意義究竟何在呢?這種新的秘密共享方案直到 1983 年才被提出,想必是為瞭解決某個以前不曾有過的需求。 20 世紀中後期究竟出現了什麼?答案便是——計算機網絡。鎖孔方案只適用於物理世界,不能用於網絡世界。為了在網絡世界中共享秘密,我們需要一種純信息層面的、只涉及數據交換的新方法, Mignotte 秘密共享方案才應運而生。
數論知識開始煥發新生,一切都是因為這該死的計算機網絡。
(五)公鑰加密的可能性
計算機網絡的出現無疑降低了交流的成本,但卻給信息安全帶來了難題。在計算機網絡中,一切都是數據,一切都是數字,一切都是透明的。假如你的朋友要給你發送一份絕密文件,你如何阻止第三者在你們的通信線路的中間節點上竊走信息?其中一種方法就是,讓他對發送的數據進行加密,密碼只有你們兩人知道。但是,這個密碼又是怎麼商定出來的呢?直接叫對方編好密碼發給你的話,密碼本身會有洩漏的風險;如果讓對方給密碼加個密再發過來呢,給密碼加密的方式仍然不知道該怎麼確定。如果是朋友之間的通信,把兩人已知的小秘密用作密鑰(例如約定密鑰為 A 的生日加上 B 的手機號)或許能讓人放心許多;但對於很多更常見的情形,比方說用戶在郵件服務提供商首次申請郵箱時,會話雙方完全沒有任何可以利用的公共秘密。此時,我們需要一個絕對邪的辦法……如果說我不告訴任何人解密的算法呢?這樣的話,我就可以公開加密的方法,任何人都能夠按照這種方法對信息進行加密,但是只有我自己才知道怎樣給由此得到的密文解密。然後,讓對方用這種方法給文件加密傳過來,問題不就解決了嗎?這聽上去似乎不太可能,因為直覺上,知道加密的方法也就知道瞭解密的方法,只需要把過程反過來做就行了。加密算法和解密算法有可能是不對稱的嗎?
有可能。小時候我經常在朋友之間表演這麼一個數學小魔術:讓對方任意想一個三位數,把這個三位數乘以 91 的乘積的末三位告訴我,我便能猜出對方原來想的數是多少。如果對方心裡想的數是 123 ,那麼對方就計算出 123 × 91 等於 11193 ,並把結果的末三位 193 告訴我。看起來,這麼做似乎損失了不少信息,讓我沒法反推出原來的數。不過,我仍然有辦法:只需要把對方告訴我的結果再乘以 11 ,乘積的末三位就是對方剛開始想的數了。你可以驗證一下, 193 × 11 = 2123 ,末三位正是對方所想的秘密數字!其實道理很簡單, 91 乘以 11 等於 1001 ,而任何一個三位數乘以 1001 後,末三位顯然都不變(例如 123 乘以 1001 就等於 123123 )。先讓對方在他所想的數上乘以 91 ,假設乘積為 X ;我再在 X 的基礎上乘以 11 ,其結果相當於我倆合作把原數乘以了 1001 ,自然末三位又變了回去。然而, X 乘以 11 後的末三位是什麼,只與 X 的末三位有關。因此,對方只需要告訴我 X 的末三位就行了,這並不會丟掉信息。站在數論的角度來看,上面這句話有一個更好的解釋:反正最後都要取除以 1000 的餘數,在中途取一次餘數不會有影響(還記得嗎,「反正最後都要對乘積取餘,相乘之前事先對乘數取餘不會對結果造成影響」)。知道原理後,我們可以構造一個定義域和值域更大的加密解密系統。比方說,任意一個數乘以 500000001 後,末 8 位都不變,而 500000001 = 42269 × 11829 ,於是你來乘以 42269 ,我來乘以 11829 ,又一個加密解密不對稱的系統就構造好了。這是一件很酷的事情,任何人都可以按照我的方法加密一個數,但是只有我才知道怎麼把所得的密文變回去。在現代密碼學中,數論漸漸地開始有了自己的地位。
不過,加密和解密的過程不對稱,並不妨礙我們根據加密方法推出解密方法來,雖然這可能得費些功夫。比方說,剛才的加密算法就能被破解:猜出對方心裡想的數相當於求解形如 91x mod 1000 = 193 的方程,這可以利用擴展的輾轉相除法很快求解出來,根本不需要其他的彫蟲小技(注意到 91 和 1000 是互質的,根據 Bézout 定理,方程確實保證有解)。為了得到一個可以公開加密鑰匙的算法,我們還需要從理論上說服自己,在只知道加密鑰匙的情況下構造出解密鑰匙是非常非常困難的。
1970 年左右,科學家們開始認真地思考「公鑰加密系統」的可能性。 1977 年,來自 MIT 的 Ron Rivest 、 Adi Shamir 和 Leonard Adleman 三個人合寫了一篇論文,給出了一種至今仍然安全的公鑰加密算法。隨後,該算法以三人名字的首字母命名,即 RSA 算法。
RSA 算法為什麼會更加安全呢?因為 RSA 算法用到了一種非常犀利的不對稱性——大數分解難題。
為了判斷一個數是不是質數,最笨的方法就是試除法——看它能不能被 2 整除,如果不能的話再看它能不能被 3 整除,這樣不斷試除上去。直到除遍了所有比它小的數,都還不能把它分解開來,它就是質數了。但是,試除法的速度太慢了,我們需要一些高效的方法。 Fermat 素性測試就是一種比較常用的高效方法,它基於如下原理: Fermat 小定理對一切質數都成立。回想 Fermat 小定理的內容:如果 n 是一個質數的話,那麼對於任意一個數 a , a 的 n 次方減去 a 之後都將是 n 的倍數。為了判斷 209 是不是質數,我們隨便選取一個 a ,比如 38 。結果發現,38209 - 38 除以 209 余 114 (稍後我們會看到,即使把 209 換成上百位的大數,利用計算機也能很快算出這個餘數來),不能被 209 整除。於是, 209 肯定不是質數。我們再舉一個例子。為了判斷 221 是不是質數,我們隨機選擇 a ,比如說還是 38 吧。你會發現 38221 - 38 除以 221 正好除盡。那麼, 221 是否就一定是質數了呢?麻煩就麻煩在這裡:這並不能告訴我們 221 是質數,因為 Fermat 小定理畢竟只說了對一切質數都成立,但沒說對其他的數成不成立。萬一 221 根本就不是質數,但 a = 38 時碰巧也符合 Fermat 小定理呢?為了保險起見,我們不妨再選一個不同的 a 值。比方說,令 a = 26 ,可以算出 26221 - 26 除以 221 余 169 ,因而 221 果然並不是質數。這個例子告訴了我們,如果運氣不好的話,所選的 a 值會讓不是質數的數也能騙過檢測,雖然這個概率其實並不大。因此,我們通常的做法便是,多選幾個不同的 a ,只要有一次沒通過測試,被檢測的數一定不是質數,如果都通過測試了,則被檢測的數很可能是質數。沒錯, Fermat 素性測試的效率非常高,但它是基於一定概率的,有誤報的可能。如果發現某個數 n 不滿足 Fermat 小定理,它一定不是質數;但如果發現某個數 n 總能通過 Fermat 小定理的檢驗,只能說明它有很大的幾率是質數。
Fermat 素性測試真正麻煩的地方就是,居然有這麼一種極其特殊的數,它不是質數,但對於任意的 a 值,它都能通過測試。這樣的數叫做 Carmichael 數,最小的一個是 561 ,接下來的幾個則是 1105, 1729, 2465, 2821, 6601, 8911… 雖然不多,但很致命。因此,在實際應用時,我們通常會選用 Miller-Rabin 素性測試算法。這個算法以 Gary Miller 的研究成果為基礎,由 Michael Rabin 提出,時間大約是 1975 年。它可以看作是對 Fermat 素性測試的改良。如果選用了 k 個不同的 a 值,那麼 Miller-Rabin 素性測試算法出現誤判的概率不會超過 1 / 4k ,足以應付很多現實需要了。
有沒有什麼高效率的、確定性的質數判定算法呢?有,不過這已經是很後來的事情了。 2002 年, Manindra Agrawal 、 Neeraj Kayal 和 Nitin Saxena 發表了一篇重要的論文 PRIMES is in P ,給出了第一個高效判斷質數的確定性算法,並以三人名字的首字母命名,叫做 AKS 素性測試。不過,已有的質數判斷算法已經做得很好了,因此對於 AKS 來說,更重要的是它的理論意義。
有了判斷質數的算法,要想生成一個很大的質數也並不困難了。一種常見的做法是,先選定一串連續的大數,然後去掉其中所有能被 2 整除的數,再去掉所有能被 3 整除的數,再去掉所有能被 5 整除的數……直到把某個範圍內(比如說 65000 以內)的所有質數的倍數全都去掉。剩下的數就不多了,利用判斷質數的算法對它們一一進行測試,不久便能找出一個質數來。
怪就怪在,我們可以高效地判斷一個數是不是質數,我們可以高效地生成一個很大的質數,但我們卻始終找不到高效的大數分解方法。任意選兩個比較大的質數,比如 19394489 和 27687937 。我們能夠很容易計算出 19394489 乘以 27687937 的結果,它等於 536993389579193 ;但是,除了試除法以外,目前還沒有什麼本質上更有效的方法(也很難找到更有效的方法)能夠把 536993389579193 迅速分解成 19394489 乘以 27687937 。這種不對稱性很快便成了現代密碼學的重要基礎。讓我們通過一個有趣的例子來看看,大數分解的困難性是如何派上用場的吧。
假如你和朋友用短信吵架,最後決定拋擲硬幣來分勝負,正面表示你獲勝,反面表示對方獲勝。問題來了——兩個人如何通過短信公平地拋擲一枚硬幣?你可以讓對方真的拋擲一枚硬幣,然後將結果告訴你,不過前提是,你必須充分信任對方才行。在雙方互不信任的情況下,還有辦法模擬一枚虛擬硬幣嗎?在我們生活中,有一個常見的解決方法:考你一道題,比如「明天是否會下雨」、「地球的半徑是多少」或者「《新華字典》第 307 頁的第一個字是什麼」,猜對了就算你贏,猜錯了就算你輸。不過,上面提到的幾個問題顯然都不是完全公平的。我們需要一類能快速生成的、很難出現重複的、解答不具技巧性的、猜對猜錯幾率均等的、具有一個確鑿的答案並且知道答案後很容易驗證答案正確性的問題。大數分解為我們構造難題提供了一個模板。比方說,讓對方選擇兩個 90 位的大質數,或者三個 60 位的大質數,然後把乘積告訴你。無論是哪種情況,你都會得到一個大約有 180 位的數。你需要猜測這個數究竟是兩個質數乘在一起得來的,還是三個質數乘在一起得來的。猜對了就算正面,你贏;猜錯了就算反面,對方贏。宣佈你的猜測後,讓對方公開他原先想的那兩個數或者三個數,由你來檢查它們是否確實都是質數,乘起來是否等於之前給你的數。
大數分解難題成為了 RSA 算法的理論基礎。
(六)RSA 算法
所有工作都準備就緒,下面我們可以開始描述 RSA 算法了。
首先,找兩個質數,比如說 13 和 17 。實際使用時,我們會選取大得多的質數。把它們乘在一起,得 221 。再計算出 (13 - 1) × (17 - 1) = 192。根據前面的結論,任選一個數 a ,它的 i 次方除以 221 的餘數將會呈現長度為 192 的週期(雖然可能存在更短的週期)。換句話說,對於任意的一個 a,a, a193, a385, a577, ... 除以 221 都擁有相同的餘數。注意到, 385 可以寫成 11 × 35 ……嘿嘿,這下我們就又能變數學小魔術了。叫一個人隨便想一個不超過 221 的數,比如 123 。算出 123 的 11 次方除以 221 的餘數,把結果告訴你。如果他的計算是正確的,你將會得到 115 這個數。看上去,我們似乎很難把 115 還原回去,但實際上,你只需要計算 115 的 35 次方,它除以 221 的餘數就會變回 123 。這是因為,對方把他所想的數 123 連乘了 11 次,得到了一個數 X ;你再把這個 X 乘以自身 35 次,這相當於你們合作把 123 連乘了 385 次,根據週期性現象,它除以 221 的餘數仍然是 123 。然而,計算 35 個 X 連乘時,反正我們要取乘積除以 221 的餘數,因此我們不必完整地獲知 X 的值,只需要知道 X 除以 221 的餘數就夠了。因而,讓對方只告訴你 X 取餘後的結果,不會造成信息的丟失。
不過這一次,只知道加密方法後,構造解密方法就難了。容易看出, 35 之所以能作為解密的鑰匙,是因為 11 乘以 35 的結果在數列 193, 385, 577, ... 當中,它除以 192 的餘數正好是 1 。因此,攻擊者可以求解 11x mod 192 = 1 ,找出滿足要求的密鑰 x 。但關鍵是,他怎麼知道 192 這個數?要想得到 192 這個數,我們需要把 221 分解成 13 和 17 的乘積。當最初所選的質數非常非常大時,這一點是很難辦到的。
根據這個原理,我們可以選擇兩個充分大的質數 p 和 q ,並算出 n = p ‧ q 。接下來,算出 m = (p - 1)(q - 1) 。最後,找出兩個數 e 和 d ,使得 e 乘以 d 的結果除以 m 余 1 。怎麼找到這樣的一對 e 和 d 呢?很簡單。首先,隨便找一個和 m 互質的數(這是可以做到的,比方說,可以不斷生成小於 m 的質數,直到找到一個不能整除 m 的為止),把它用作我們的 e 。然後,求解關於 d 的方程 e ‧ d mod m = 1(就像剛才攻擊者想要做的那樣,只不過我們有 m 的值而他沒有)。 Bézout 定理將保證這樣的 d 一定存在。
好了,現在, e 和 n 就可以作為加密鑰匙公之於眾, d 和 n 則是只有自己知道的解密鑰匙。因而,加密鑰匙有時也被稱作公鑰,解密鑰匙有時也被稱作私鑰。任何知道公鑰的人都可以利用公式 c = ae mod n 把原始數據 a 加密成一個新的數 c ;私鑰的持有者則可以計算 cd mod n ,恢復出原始數據 a 來。不過這裡還有個大問題: e 和 d 都是上百位的大數,怎麼才能算出一個數的 e 次方或者一個數的 d 次方呢?顯然不能老老實實地算那麼多次乘法,不然效率實在太低了。好在,「反覆平方」可以幫我們快速計算出一個數的乘方。比方說,計算 a35 相當於計算 a34 ‧ a ,也即 (a17)2 ‧ a ,也即 (a16 ‧ a)2 ‧ a,也即 ((a8)2 ‧ a)2 ‧ a……最終簡化為 ((((a2)2)2)2 ‧ a)2 ‧ a ,因而 7 次乘法操作就夠了。在簡化的過程中, a 的指數以成半的速度遞減,因而在最後的式子當中,所需的乘法次數也是對數級別的,計算機完全能夠承受。不過,減少了運算的次數,並沒有減小數的大小。 a 已經是一個數十位上百位的大數了,再拿 a 和它自己多乘幾次,很快就會變成一個計算機內存無法容納的超級大數。怎麼辦呢?別忘了,「反正最後都要對乘積取餘,相乘之前事先對乘數取餘不會對結果造成影響」,因此我們可以在運算過程中邊算邊取餘,每做一次乘法都只取乘積除以 n 的餘數。這樣一來,我們的每次乘法都是兩個 n 以內的數相乘了。利用這些小竅門,計算機才能在足夠短的時間裡完成 RSA 加密解密的過程。
RSA 算法實施起來速度較慢,因此在運算速度上的任何一點優化都是有益的。利用中國剩餘定理,我們還能進一步加快運算速度。我們想要求的是 a35 除以 n 的餘數,而 n 是兩個質數 p 和 q 的乘積。由於 p 和 q 都是質數,它們顯然也就互質了。因而,如果我們知道 a35 分別除以 p 和 q 的餘數,也就能夠反推出它除以 n 的餘數了。因此,在反覆平方的過程中,我們只需要保留所得的結果除以 p 的餘數和除以 q 的餘數即可,運算時的數字規模進一步降低到了 p 和 q 所在的數量級上。到最後,我們再借助「今有物,不知其數」的求解思路,把這兩條餘數信息恢復成一個 n 以內的數。更神的是,別忘了, ai 除以 p 的餘數是以 p - 1 為週期的,因此為了計算 a35 mod p ,我們只需要計算 a35 mod (p-1) mod p 就可以了。類似地,由於餘數的週期性現象,計算 a35 mod q 就相當於計算 a35 mod (q-1)mod q 。這樣一來,連指數的數量級也減小到了和 p 、 q 相同的水平, RSA 運算的速度會有明顯的提升。
需要注意的是, RSA 算法的安全性並不完全等價於大數分解的困難性(至少目前我們還沒有證明這一點)。已知 n 和 e 之後,不分解 n 確實很難求出 d 來。但我們並不能排除,有某種非常巧妙的方法可以繞過大數分解,不去求 p 和 q 的值,甚至不去求 m 的值,而直接求出一個滿足要求的 d 來。不過,即使考慮到這一點,目前人們也沒有破解密鑰 d 的好辦法。 RSA 算法經受住了實踐的考驗,並逐漸成為了行業標準。如果 A 、 B 兩個人想要建立會話,那麼我們可以讓 A 先向 B 索要公鑰,然後想一個兩人今後通話用的密碼,用 B 的公鑰加密後傳給 B ,這將只能由 B 解開。因此,即使竊聽者完全掌握了雙方約定密碼時傳遞的信息,也無法推出這個密碼是多少來。
上述方案讓雙方在不安全的通信線路上神奇地約定好了密碼,一切看上去似乎都很完美了。然而,在這個漂亮的解決方案背後,有一個讓人意想不到的、頗有些喜劇色彩的漏洞——中間人攻擊。在 A 、 B 兩人建立會話的過程中,攻擊者很容易在線路中間操縱信息,讓 A 、 B 兩人誤以為他們是在直接對話。讓我們來看看這具體是如何操作的吧。建立會話時, A 首先呼叫 B 並索要 B 的公鑰,此時攻擊者注意到了這個消息。當 B 將公鑰回傳給 A 時,攻擊者截獲 B 的公鑰,然後把他自己的公鑰傳給 A 。接下來, A 隨便想一個密碼,比如說 314159 ,然後用他所收到的公鑰進行加密,並將加密後的結果傳給 B 。 A 以為自己加密時用的是 B 的公鑰,但他其實用的是攻擊者的公鑰。攻擊者截獲 A 傳出來的信息,用自己的私鑰解出 314159 ,再把 314159 用 B 的公鑰加密後傳給 B 。 B 收到信息後不會發現什麼異樣,因為這段信息確實能用 B 的私鑰解開,而且確實能解出正確的信息 314159 。今後, A 、 B 將會用 314159 作為密碼進行通話,而完全不知道有攻擊者已經掌握了密碼。
怎麼封住這個漏洞呢?我們得想辦法建立一個獲取對方公鑰的可信渠道。一個簡單而有效的辦法就是,建立一個所有人都信任的權威機構,由該權威機構來儲存並分發大家的公鑰。這就是我們通常所說的數字證書認證機構,英文是 Certificate Authority ,通常簡稱 CA 。任何人都可以申請把自己的公鑰放到 CA 上去,不過 CA 必須親自檢查申請者是否符合資格。如果 A 想要和 B 建立會話,那麼 A 就直接從 CA 處獲取 B 的公鑰,這樣就不用擔心得到的是假的公鑰了。
新的問題又出來了:那麼,怎麼防止攻擊者冒充 CA 呢? CA 不但需要向 A 保證「這個公鑰確實是 B 的」,還要向 A 證明「我確實就是 CA 」。
把加密鑰匙和解密鑰匙稱作「公鑰」和「私鑰」是有原因的——有時候,私鑰也可以用來加密,公鑰也可以用來解密。容易看出,既然 a 的 e 次方的 d 次方除以 n 的餘數就回到了 a ,那麼當然, a 的 d 次方的 e 次方除以 n 的餘數也會變回 a 。於是,我們可以讓私鑰的持有者計算 a 的 d 次方除以 n 的餘數,對原文 a 進行加密;然後公鑰的持有者取加密結果的 e 次方除以 n 的餘數,這也能恢復出原文 a 。但是,用我自己的私鑰加密,然後大家都可以解密,這有什麼用處呢?不妨來看看這樣「加密」後的效果吧:第一,貌似是最荒謬的,大家都可以用我的公鑰解出它所對應的原始文件;第二,很關鍵的,大家只能查看它背後的原文件,不能越過它去修改它背後的原文件;第三,這樣的東西是別人做不出來的,只有我能做出來。
這些性質正好完美地描述出「數字簽名」的實質,剛才的 CA 難題迎刃而解。 CA 首先生成一個自己的公鑰私鑰對,然後把公鑰公之於眾。之後, CA 對每條發出去的消息都用自己的私鑰加個密作為簽名,以證明此消息的來源是真實的。收到 CA 的消息後,用 CA 的公鑰進行解密,如果能恢復出 CA 的原文,則說明對方一定是正宗的 CA 。因為,這樣的消息只有私鑰的持有者才能做出來,它上面的簽名是別人無法偽造的。至此為止,建立安全的通信線路終於算是有了一個比較完美的方案。
實際應用中,建立完善的安全機制更加複雜。並且,這還不足以解決很多其他形式的網絡安全問題。隨便哪個簡單的社交活動,都包含著非常豐富的協議內涵,在互聯網上實現起來並不容易。比方說,如何建立一個網絡投票機制?這裡面的含義太多了:我們需要保證每張選票確實都來自符合資格的投票人,我們需要保證每個投票人只投了一票,我們需要保證投票人的選票內容不會被洩露,我們需要保證投票人的選票內容不會被篡改,我們還需要讓唱票環節足夠透明,讓每個投票人都確信自己的票被算了進去。作為密碼學與協議領域的基本模塊, RSA 算法隨時準備上陣。古希臘數學家對數字執著的研究,直到今天也仍然綻放著光彩。
沒有留言:
張貼留言